PE3_11 PE头_解析手动
内存对齐
在硬盘和内存中的程序数据可能会有所不同,原因是内存对齐。对齐的作用在于加快内存访问的速度。
文件在内存中的分节存储
- 程序文件在内存中被分为不同的段(sections)存储。
- 不同段之间通常有填充字节(例如0),但有些段可以被多个程序共享,以节省内存资源。
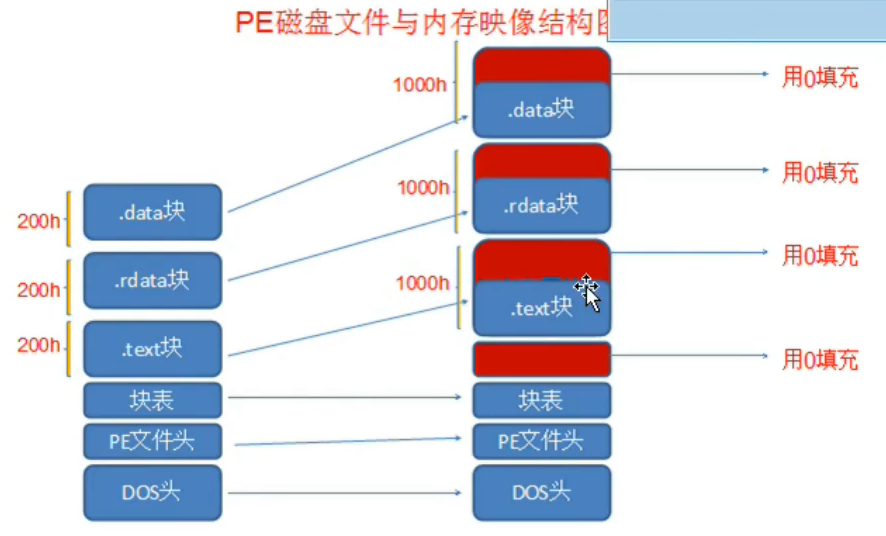
可以看到段与段之间有很多0填充,比如说数据段,但是有些段可以共用,比如多开程序,共享一个数据区域,节省内存
程序运行时的变化
- 从硬盘加载到内存时,程序会根据文件格式进行相应的布局变化。硬盘中的文件格式与内存中的程序结构并不完全相同,内存对齐会造成某些数据的拉伸和填充。
需要记住的关键结构
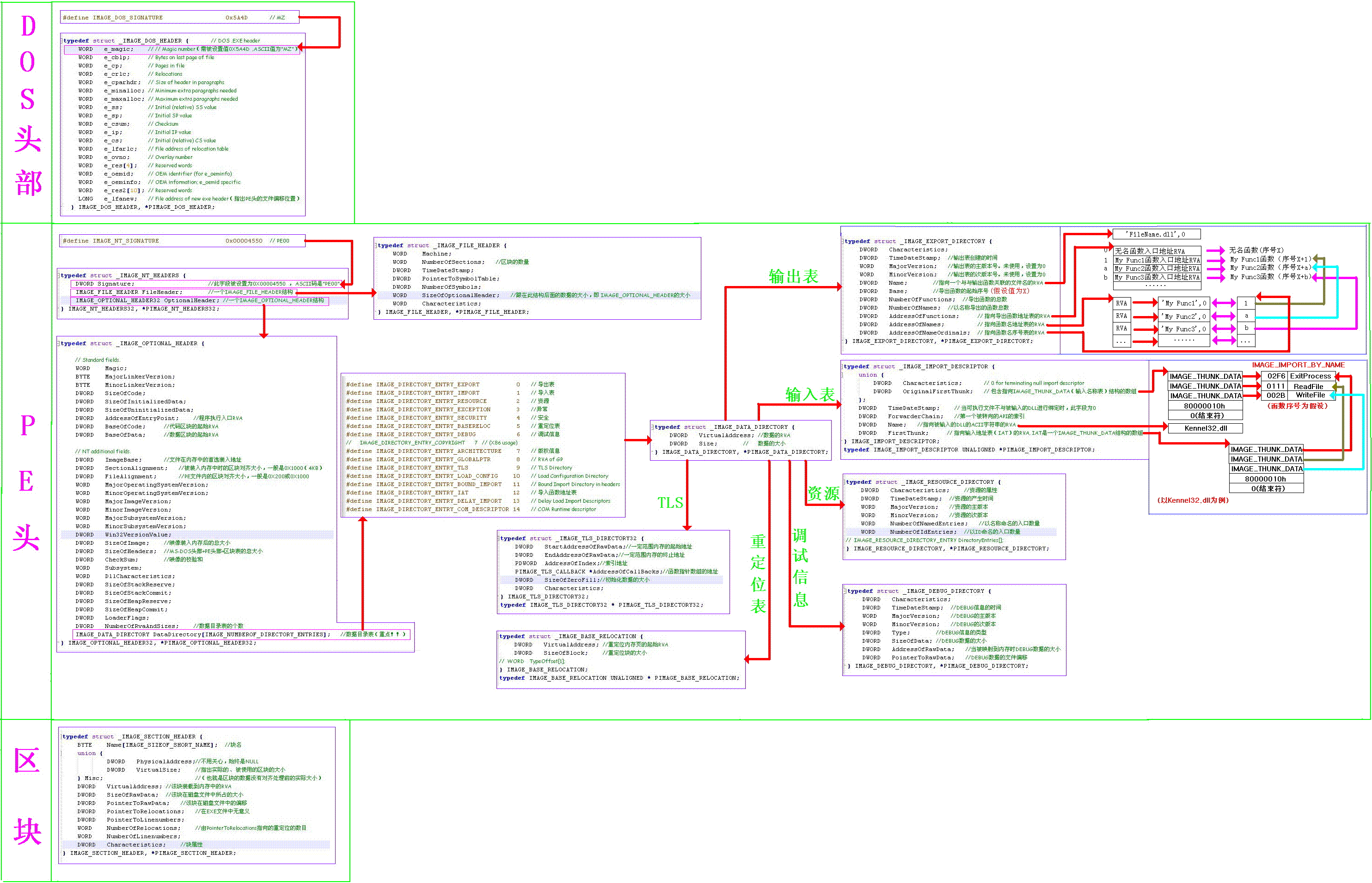
DOS头
- MZ标志位(程序以“MZ”开头)
- PE标识偏移(指向PE头的偏移)
标准PE头
- PE标识位:
PE\x00\x00 - 目标处理器类型(CPU类型)
- 区段数(Section数量)
- 选项头大小(Optional Header Size)
- 特征值(文件属性标志)
- PE标识位:
可选PE头
- 标志位
- 所有代码区块总大小
- 所有初始化数据区段总大小
- 所有未初始化区块总大小
- 程序入口点(OEP, Original Entry Point)
- 代码区段初始RVA(Relative Virtual Address)
- 数据区域初始RVA
- 映像基址(Image Base)
- 内存区段对齐大小
- 文件区段对齐大小
- 内存中映像总尺寸
- 头部大小(DOS、PE头的总大小)
- 校验和
- 初始化堆栈大小
- 实际提交堆栈大小
- 初始化堆栈保留大小
为什么通过PE标识偏移找到PE头?
PE头通过PE标识偏移来定位,这是因为编译过程中可能会插入一些额外的垃圾数据。这与历史原因有关,特别是在兼容旧的DOS程序时,因此需要通过偏移找到正确的PE头。
这种方式确保即使在存在垃圾数据的情况下,仍然可以正确解析出PE头并加载程序。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Hexo!